
Pythonで共分散行列を求める

グローバルウェイのYです。
共分散は、2つの変数が「一緒にどれくらい変動するか」を測る指標です。
- 正の共分散:片方が増えると、もう片方も増える傾向がある
- 負の共分散:片方が増えると、もう片方は減る傾向がある
この考え方を、複数の特徴量に拡張したものが共分散行列です。
この記事は以下のターゲットを対象としています。
★5 Djangoの開発経験が3年以上。
★4 Djangoの開発経験が1年以上。
★3 Webサイト開発経験あり。これからDjangoを学習します。
★2 Python 初級者。簡単なプログラムコードが書けます。
★1 プログラミング未経験。
なぜ共分散行列を見るのか
共分散行列は、各変数の分散(対角成分)と、変数間の共分散(非対角成分)をまとめた行列で、データの構造を理解するための基本ツールです。
Pythonの資格を目指す人にとってもっとも身近な使用法は主成分分析(PCA)です。
PCAでは、この行列を固有値分解し、データのばらつきを説明する主成分方向を抽出します。固有値は「その方向の情報量(分散)」を示し、固有ベクトルは「その方向の軸」を表します。
共分散行列を理解することは、次元削減や特徴抽出の本質を理解する第一歩です。単にライブラリのメソッドを呼び出すだけでなく、「なぜその処理が必要なのか」を理解しておくことは、実務でも試験でも大きな価値があります。
標本共分散とは
サンプルサイズ n の 2 変数 x,y の共分散は:
$$\text{Cov}(X, Y) = \frac{1}{n-1} \sum_{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y})$$
ここで:
- $x_i, y_i$:それぞれの観測値
- $\bar{x}, \bar{y}$:各変数の標本平均
この考え方を複数の特徴量に拡張すると、共分散行列になります:
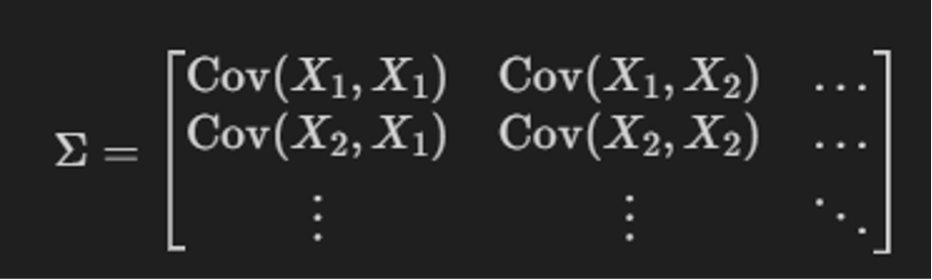
- 対角成分:各変数の分散 $(\text{Var}(X_i))$
- 非対角成分:変数間の共分散 $(\text{Cov}(X_i, X_j))$
共分散行列の特徴は以下のとおりです
- 対称行列
共分散行列は $\Sigma = [\text{Cov}(X_i, X_j)]$ で構成され、
$\text{Cov}(X_i, X_j) = \text{Cov}(X_j, X_i)$ なので、行列は必ず対称です。 - 共分散行列は、任意の非ゼロベクトル $a$ に対して
$$a^\top \Sigma a \ge 0$$
が成り立ちます。これは、分散が負にならないことに対応します。 - 対角成分は分散(2次のモーメント)
$$\Sigma_{ii} = \text{Var}(X_i) = E[(X_i - \mu_i)^2]$$ - サイズは特徴量の数に依存
特徴量が $p$ 個なら、共分散行列は$p \times p$ の正方行列になります。 - スケール依存性がある
単位やスケールが異なると、共分散の絶対値が変わります。
今回は標準化します。 - 固有値分解が可能
共分散行列は対称かつ正定値なので、固有値分解できます。
$$\Sigma = Q \Lambda Q^\top$$
固有値 $Λ$:各主成分の分散
固有ベクトル $Q$:主成分の方向
プログラムで共分散行列を作成する
今回はアヤメのデータをすべて使用します。
アヤメのデータについては
https://gw-python.com/archives/502
をご覧ください。
アヤメのデータは以下の三つの品種のデータをもちます。
setosa, versicolor, virginica
また、それぞれ、以下の特徴量を持ちます。
sepal length, sepal width, petal length, petal width
では、共分散行列を作成します。
今回はプログラム内で標準化をしています。標準化については
https://gw-python.com/archives/589
をご覧ください。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
# 1) Irisデータ読み込み
iris = load_iris()
X = iris.data # shape: (150, 4)
feature_names = iris.feature_names
# 2) 標準化(scikit-learnのStandardScaler)
scaler = StandardScaler()
X_std = scaler.fit_transform(X) # 平均0・分散1に変換
# 3) 共分散行列(NumPyで標本共分散)
cov_matrix = np.cov(X_std, rowvar=False, bias=False) # rowvar=False: 列を変数、bias=False: n-1で割る
# 出力
np.set_printoptions(precision=3, suppress=True)
print("=== 共分散行列(標準化後・標本) ===")
print(cov_matrix)実行結果
=== 共分散行列(標準化後・標本) ===
[[ 1.007 -0.118 0.878 0.823]
[-0.118 1.007 -0.431 -0.369]
[ 0.878 -0.431 1.007 0.969]
[ 0.823 -0.369 0.969 1.007]]まとめ
共分散行列の求め方を式で示しました。実際にPCAをプログラムで行う場合は、ライブラリにメソッドが用意されているため、このようなコードを書くことはほとんどありません。しかし、処理の中で何が行われているかを理解しておくことは非常に重要です。
実際のPCAでは、このあと固有値を求め、そこから寄与率(分散説明率)を算出して主成分を選びます。
今回は内容を絞り、共分散行列の求め方のみを解説します。難しい式ではありません。
ぜひ勉強して、理解を深めてみてください。

