
「openpyxl」を使って、セルの値を取り出してみる。

※社外のコラムニストによる記事です。Python関連の情報をお伝えします。
「シゴトがはかどるPython自動処理の教科書(著:クジラ飛行机様/マイナビ出版)」を利用して、Pythonを使った自動化について学んでいきます。
前回は、Excelの機能のひとつ、数式と組み合わせて使う方法について学びました。
今回は、Chapter2-5 Excelシートを連続で読み込む方法についてです。
目次
ワークシートからセルの値を読み込む基本的な方法
まず、Excelワークシートからセルの値を読み取るときの基本的な方法です。テキストには以下が紹介されていました。
P.61 (1)A5やC8など「セル名」を指定して値を読む
print(sheet[“セル名”.value])(2)行番号と列番号を指定して値を取得(rowとcolumnは1起点)
v = sheet.cell(row=行番号, column=列番号).value
print(v)(※テキストではprint( v )のように書かれていますが、PEP8的に不要なスペースのため削除しています。)
(1)の方法はセル名を指定してシートの値を読み取ります。
そして、(2)の方法では、cellメソッドを使います。行番号と列番号を名前つき引数で指定して値を得ます。
(中略)
(1)と(2)共通ですが、セルに値が設定されていれば値が得られ、値が何も設定されていなければNoneが得られます。
ちなみに、(2)の方法について、値を後で利用する場合などでは変数を利用した方が便利になりますが、変数を使うほどのものではない場合は、シンプルに以下のように書くこともできます。
print(sheet.cell(行番号, 列番号).value)
print(sheet.cell(row=行番号, column=列番号).value)
ではここでサンプルコードです。シンプルバージョンも一緒に追記して実行してみました。
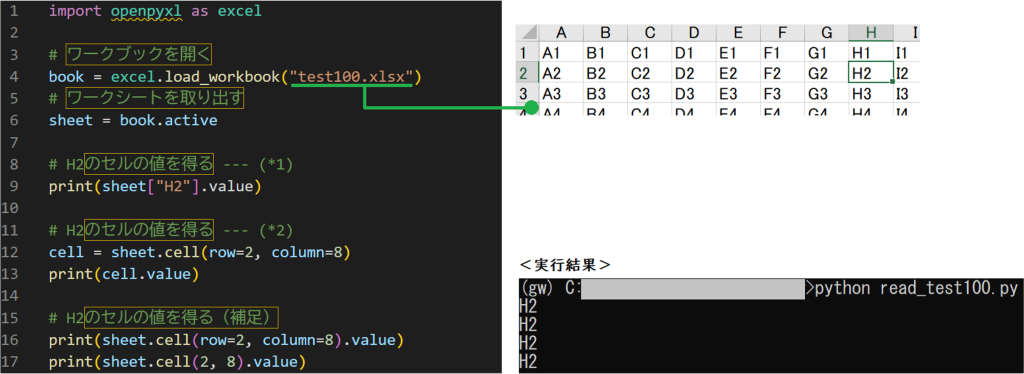
問題なく結果が表示されました。
Excelファイルから連続するデータを取り出して見る
では次にExcelファイルから連続するデータを取り出したい場合の方法です。3つあります。
(1)for文を利用して1つずつ範囲内のセルを得る
(2)ワークシートの特定の範囲を取り出す方法
取り出すためのExcelファイルは先ほど利用したExcelファイルと同じもので、取得するデータはB2からD4です。
1.for文を利用して1つずつ範囲内のセルを得る
まずは1つ目です。
P.64
方法1は、すでに学んだ方法をfor文と組み合わせるものです。縦方向と横方向、二重にfor文を仕掛けることで、もれなく範囲内のセルの値を得ます。
import openpyxl as excel
# ワークブックを開いてシートを得る --- (*1)
book = excel.load_workbook("test100.xlsx")
sheet = book.active
# 連続でセルの値を得て表示 --- (*2)
for y in range(2, 5):
r = []
for x in range(2, 5):
v = sheet.cell(row=y, column=x).value
r.append(v)
print(r)Excelには0行目、0列目がないので、1からスタートします。そのため、rangeで指定されるのは(1, 5)ではなく、(2, 5)です。つまり、2~4行目、2~4列目となります。取り出したデータは変数rにリストとして保管し、最後のprint()で表示します。
[v = sheet.cell(row=y, column=x).value]は繰り返し処理で取得した行・列の値を代入し、[.value]で指定されたセルの値を取得し、変数vに入れる処理です。その後、vに入った値をリストの末尾に入れる処理[append()]が行われるという流れだそうです。
2.ワークシートの特定の範囲を取り出す方法
2つ目の方法です。
この方法では、取得する範囲として、始まりのセル(左上)から終わりのセル(右下)を指定して、情報を二次元のタプルとして取得する方法になるそうで、書式としては次の通りとのこと。
1)
rows = sheet[“左上セル名1”:”右下セル名2”]2)
rows = rows = sheet[“左上セル名1”:”右下セル名2”]「“」の位置が違いますが、どちらを使っても同じ範囲の情報が得られるそうです。
サンプルコードをまずみてみます。サンプルコードは1の方法で記述されています。
P.65
import openpyxl as excel
# ワークブックを開いてシートを取り出す
book = excel.load_workbook("test100.xlsx")
sheet = book.active
# 連続でセルの値を得る
for row in sheet["B2":"D4"]:
r = []
for cell in row:
r.append(cell.value)
print(r)実行結果はこちら。きちんと取得できています。

リスト内包表記
ところで、このバージョンのサンプルコードはもう一つ用意されており、先ほどのコードの一部を、リスト内包表記によって短くしたというものです。一応、次の章で出てくると書かれているのですが、該当箇所を読んでもあまり詳細に書かれていないようなので、簡単に調べてみました。
リスト内包表記は[処理 for 変数 in イテラブル]という書式になっており、使う時にはこのような感じで使うそうです。
新リスト名 = []
for 変数 in イテラブル:
新リスト名.append(処理)これを[]で囲むと出力の形はリストになり、{}で囲むとセット型になるとのこと。
イテラブルとは繰り返し可能なオブジェクトの総称で、リストやタプル、文字列などが当たります。
なので、先ほどのコードで行くと、「①空のリストを作り」、「②セルをループして周り」、「③取得した値を作ったリストに入れ」、「④リストの中身をprintで表示する」という4つの処理がありますが、この部分を、
for row in sheet["B2":"D4"]:
r = [] ・・・①
for cell in row: ・・・②
r.append(cell.value) ・・・③
print(r) ・・・④このように書くと、
for row in sheet["B2":"D4"]:
print([c.value for c in row])2行にまで簡略化できるそうです。
慣れるまではキッチリ書いて何をリストに入れるのかを考えてリスト内包表記にしていくとスムーズに書けるようになる、とのこと…。
3.iter_rowsで繰り返し指定範囲を得る方法
3つ目の方法です。
P.66
イテレータ(後述)を利用して繰り返し指定範囲を取得する方法を紹介します。以下の方法では行番号と列番号を利用して任意の範囲を取得します。この方法ではリストやタプルが得られる訳でなく、イテレータが得られるので、必要に応じてfor文やlist関数などと組み合わせて利用します。
# 行番号・列番号を指定してイテレータを取得
it = sheet.iter_rows(
min_row=最小行, max_row=最大行,
min_col=最小行, max_col=最大行,
# for文と組み合わせてセルの値を得る
for row in it:
for cell in row:
print(cell.value)このiter_rowsメソッドは任意の引数を省略できます。max_rowやmax_colの引数を省略すると最小行、最小列以降のすべて値を取得できます。さらに、引数を省略するすべてのセルが得られます。
こちらがサンプルコードです。
import openpyxl as excel
# ワークブックを開いてシートを取り出す
book = excel.load_workbook("test100.xlsx")
sheet = book.active
# イテレータを取得する --- (*1)
it = sheet.iter_rows(
min_row=2, min_col=2, #行・列番号で最小行、最小列を指定
max_row=4, max_col=4) #行・列番号で最大行、最大列を指定
# for文で繰り返し値を得る --- (*2)
for row in it:
r = []
for cell in row:
r.append(cell.value)
print(r)実行結果がこちら。

先ほどと同じものが出力されました。
文中にあるイテレータに関する部分を次に引用します。
P.67
Pythonの「イテレータ(iterator)」はfor構文と組み合わせて使う、要素を反復して値を取り出す機能のことです。イテレータを使って反復可能なオブジェクトの代表にはリストやタプル、range関数などがあります。
先ほどのリスト内包表記のところで出てきたイテラブルの1種だそうで、イテラブルなオブジェクトから要素を取り出すオブジェクトとのこと。組み込み関数のnext関数でデータ(要素)を1つずつ取り出していくことができるそうです。
それではきりが良いのでこちらで終了です。今回もお付き合いいただき、ありがとうございました。
Pythonの自動化で業務の効率化を図りたい方は、グローバルウェイに依頼してみてはいかがでしょうか?興味がある方は以下をご覧の上、是非お問い合わせください。
Pythonによる業務の自動化ソリューション
このページではPythonを活用した業務の自動化ソリューションをご紹介します。 目次お客様の課題日本企業の雑務の平均時間は業務の自動化を採用するメリット当社のPythonに…


