
Pythonによる業務効率化: テキスト検索自動化

この記事は以下のターゲットを対象としています。
★4 Python開発経験が3年以上。
★3 Python開発経験が1年以上
★2 Python 初級者。簡単なプログラムコードが書けます。
★1 プログラミング未経験。
こんにちは、グローバルウェイの新田です。
Pythonを使った業務効率化の実装例について紹介します。
Pythonによる業務効率化については「業務効率化へのPythonの始め方」第一回「まずはPythonで出来ることを解説」 の記事でも紹介されていますので、ご参照ください。
目次
この記事を読んでできるようになること
- Pythonからコマンドプロンプト処理を実行する
- Pythonによるテキスト処理
- Pythonによるファイル処理
背景・目的
弊社では過去に開発したプロジェクトのPython, Djangoなどのバージョンアップ作業を行うことがあります。そのときは以下の手順に沿って作業を実施しております。
- Pythonであれば、各バージョンのリリースノート(例: What's New In Python 3.11 — Python 3.11.8 ドキュメント )の中にバージョンアップ対応が必要なものが一覧で記載されています。
- それらがプロジェクト内のソースコードで使用されているか判定するためのキーワードを抜き出します。
- ソースコード全体に対して、抜き出したキーワードで検索を行い、使用箇所を洗い出します。
- 使用箇所に対して、改修が必要か判断、必要であればバージョンアップ対応作業を行います。
この中で検索処理を行うためのツールとしてサクラエディタを使っていますが、サクラエディタでGUIから検索処理を行おうとすると、毎回キーワードを入力して検索をしなければなりません。
検索すべきキーワード数が多いと、検索処理だけでもかなりの時間を要する作業となります。
そこで、検索キーワード一覧とソースコードを指定するだけで、検索と結果の出力まで自動的に実行できるプログラムをPythonで作成し、効率化を図ってみました。
本記事で使用しているツール・環境
動作環境
本記事では以下の環境で動作確認を行っています。
- OS: Windows11 Pro
- Python: Version 3.11.3
- サクラエディタ: 32bit版, Version 2.4.2.6048
- JupyterLab: Version 4.0.10
サクラエディタとは
https://sakura-editor.github.io
Windowsのメモ帳と同じテキストエディタの一つですが、様々な編集・表示・検索機能などがあり、かつ軽量に動作するフリーソフトです。
サクラエディタでGrep検索処理
コマンドプロンプトから実行
検索処理の自動化を行うにあたり、最初にサクラエディタとPythonの連携方法を検討する必要があります。サクラエディタは通常はGUIツールとして使われますが、検索処理はコマンドプロンプトからでも実行できるようになっています。
Pythonとの連携処理(検索方法の指示と結果の受け取り)を考えると、GUIよりコマンドプロンプト経由でやり取りする方が簡単なので、コマンドプロンプト方式を採用することにします。
動作確認のために以下の簡単なテキストファイル test.txtをC:\testディレクトリ配下に作成して、検索処理ができるか試してみます。
hoge
123hoge
foohogeサクラエディタの検索処理を呼び出します。コマンドを実行するとサクラエディタの画面が立ち上がり、すぐに自動的に終了します。リダイレクト先のファイル result.logに検索結果が書き込まれます。
※皆さんの環境で動作確認する場合、サクラエディタの実行ファイルのパスは各自インストールした場所に合わせて修正してください。
> C:\soft\sakura\sakura.exe -GREPMODE -GKEY="3hoge" -GFILE="*.txt" -GFOLDER="C:\test" -GCODE=99 -GOPT:PSU1 > C:\test\result.logresult.logファイル
□検索条件 "3hoge"
検索対象 *.txt
フォルダー C:\test
除外ファイル
除外フォルダー
(サブフォルダーも検索)
(英大文字小文字を区別しない)
(文字コードセットの自動判別)
(一致した行を出力)
C:\test\test.txt(2,3) [UTF-16]: 123hoge
1 個が検索されました。この検索結果のファイルから検索条件および検索結果をまとめて確認することができます。
オプションの説明
-GREPMODE オプションを指定するとGrep検索が実行されます。
GUIの方でこの検索機能を使う場合は、メニューバー → 検索 → Grep から使えます。
コマンドラインのオプションはGUIのメニューと対応しています。
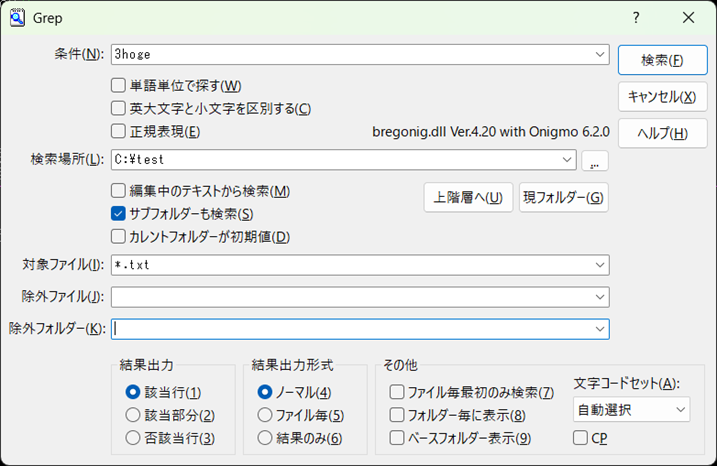
- -GKEY: 条件 (検索キーワード)
- -GFOLDER: 検索場所
- -GFILE: 検索対象ファイル
- 検索対象から除外したいファイルは先頭に!を付加、除外したいフォルダは先頭に#を付加する
- 複数の条件を組み合わせるときは;で結合
- 例:
-GFILE=*.txt;!.exe;#.git
- -GCODE: 文字コードセット (99指定で自動選択)
- -GOPT: 結果出力、結果出力形式、その他のオプション
その他のオプション詳細はサクラエディタのコマンドラインオプションのページ をご参照ください。
Pythonでコマンドプロンプトを実行する
次にPythonから任意のコマンドを実行するプログラムを紹介します。
本記事ではPythonのプログラムはJupyterLab上で実行していきます。JupyterLabではセル単位でコードを実行します。他のセルで生成した変数を共有して使うことができるため、今回のように小さいプログラムを書いて、動作確認しながら進めるときにはおすすめのツールです。
JupyterLabはデフォルトではPythonにインストールされていないため、以下のコマンドを使ってインストールし、起動してください (詳細はJupyterLabのinstallページを参照してください)。
# インストール
pip install jupyterlab
# 起動
jupyter lab起動するとwebブラウザ上にJupyterLabの画面が表示されます。

Notebookのすぐ下のPython 3をクリックすると、Untitled.ipynbというタブが表示された新しい画面に移動します。
この画面内にある青枠の入力フォームがセルと呼ばれるものです。この中にコードを記載します。
選択中のセルを実行するときはメニュー部分の▶のボタンをクリックします。
セルを追加するときはセルの右側に表示されているショートカットボタンをクリックします。
JupyterLabの使用準備が整ったので、さっそくPythonのコードを実行していきましょう。
コマンドを実行するためにはsubprocessモジュールを使用します。このモジュールはPythonにデフォルトで入っているため、追加のインストール作業は不要です。
import subprocess
# 標準出力の結果を取得するためにstdout=subprocess.PIPE を付ける(stderrも同様)
# Windowsの組み込みコマンドを実行する場合 shell=True とする
proc = subprocess.run([r"dir", r"C:\test"], stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=True)
# コマンドプロンプトの文字コードはデフォルトではcp932
print(proc.stdout.decode("cp932"))上記を実行すると以下のように、コマンドプロント上でdir C:\testコマンドを実行したときと同様の出力が表示されます (一部抜粋)。
C:\test のディレクトリ
2024/04/26 12:31 <DIR> .
2024/04/26 12:32 378 result.log
2024/04/26 12:22 46 test.txt
2 個のファイル 424 バイト
1 個のディレクトリ 778,402,037,760 バイトの空き領域Pythonからサクラエディタの検索処理実行
上記2つの処理を組み合わせ、PythonからサクラエディタのGrep検索処理を呼び出してみます。
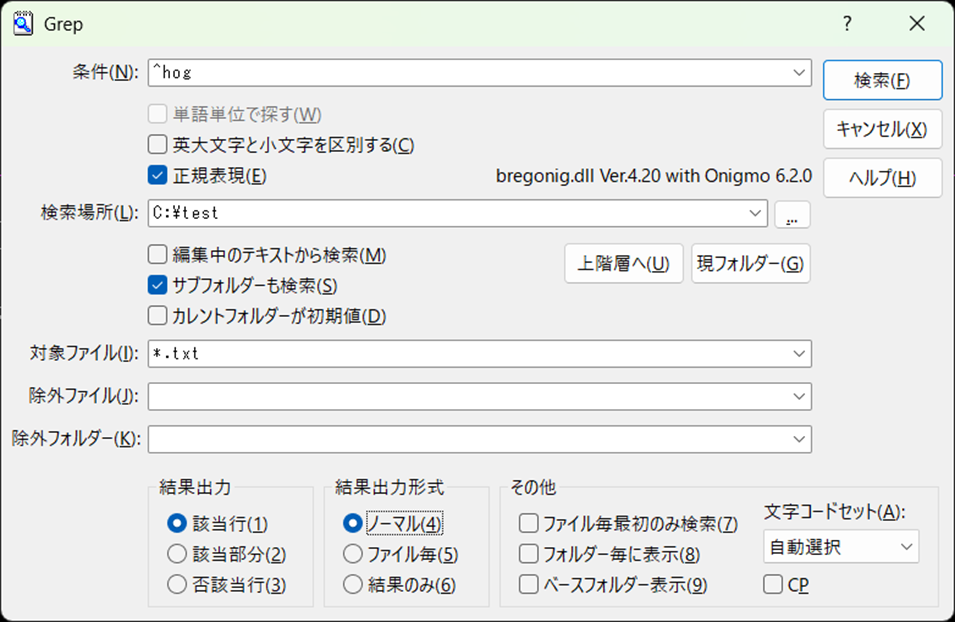
正規表現オプションを有効にし(-GOPTにRオプションを追加)、先頭がhogで始まるものだけ検索しています。
import subprocess
cmds = [
r"C:\soft\sakura\sakura.exe",
r"-GREPMODE",
r"-GKEY=^hog",
r"-GFILE=*.txt",
r"-GFOLDER=C:\test",
r"-GCODE=99",
r"-GOPT=SPU1R",
]
proc = subprocess.run(cmds, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
print(proc.stdout.decode("utf8")) # サクラエディタからの出力はutf8形式となる
print(proc.stderr.decode("utf8")) # エラーがあった場合はprintされる □検索条件 "^hog"
検索対象 *.txt
フォルダー C:\test
除外ファイル
除外フォルダー
(サブフォルダーも検索)
(英大文字小文字を区別しない)
(正規表現:bregonig.dll Ver.4.20 with Onigmo 6.2.0)
(文字コードセットの自動判別)
(一致した行を出力)
C:\test\test.txt(1,1) [UTF-16]: hoge
1 個が検索されました。この条件はサクラエディタの画面で表すと以下となります。
実行結果はPythonで文字列型データとして取得できます。検索結果のヒット数を取得したい場合は文字列検索のモジュールを使うことで実現できます。
# ヒット数を抽出する
import re
result_str = proc.stdout.decode("utf8")
hit_str = result_str.split('\r\n')[-2] # 末尾から2行目を取得
hit_cnt = re.search(r'(\d)+ 個が検索', hit_str).group(1)
print(hit_cnt)1検索キーワード一覧への検索処理を自動化
ここまでの実装を組み合わせることで、キーワードを指定して検索→結果取得の繰り返し作業を自動化することが可能となります。
どこまで自動化機能を作りこむかは再利用性・汎用性・データのバリエーションなどに応じて変わってきますが、この記事では以下の仕様でやってみます。
- grep検索の呼び出し処理を関数化
- 検索するキーワードの一覧をエクセルファイルで作成し、Pythonで読み込み
- 全検索結果について、検索キーワードと検索結果件数をprint出力
- サクラエディタの検索結果ログは、ログファイルとしてまとめて出力
- プログラムの実行はローカル環境のPC上で手動で行う
まずは、grep検索の処理を関数化します。これまでは引数に直に値を設定している箇所がありましたが、それらを関数の引数として定義しなおし、汎用的に使えるものにします(これもどこまで汎用化するかはケースバイケースです)。
今回の例は処理の全体像を見やすくすることを優先してデフォルトオプションなどは先の処理と同じものとしています。
import re
import subprocess
def get_result_cnt(result_str: str) -> int:
"""サクラエディタの検索結果からヒット数を取得する"""
hit_str = result_str.split('\r\n')[-2] # 末尾から2行目を取得
hit_cnt = re.search(r'(\d)+ 個が検索', hit_str).group(1)
return int(hit_cnt)
def grep_sakura(
keywords: list,
files: str="*.txt",
folders: str=r"C:\test",
options: str="SPU1R",
log_file: str=r"C:\test\result.log"
):
"""
keywordsで指定された各文字列についてサクラエディタのGrep検索を実行し、
結果をlog_fileに保存する
"""
result_dict = {}
with open(log_file, mode="w", encoding="utf8", newline="\n") as f:
for keyword in keywords:
cmds = [
r"C:\soft\sakura\sakura.exe",
r"-GREPMODE",
f"-GKEY={keyword}",
f"-GFILE={files}",
f"-GFOLDER={folders}",
r"-GCODE=99",
f"-GOPT={options}",
]
proc = subprocess.run(cmds, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
result_str = proc.stdout.decode("utf8")
result_dict[keyword] = get_result_cnt(result_str)
f.write(result_str)
print(result_dict)
# 試しに実行
grep_sakura(["^hog", "123"])次に検索キーワードをエクセルから読み出す処理を作成します。
エクセルファイルは以下のデータを作成し、C:\test\table.csvとして保存します。ファイルのフォーマットはCSV UTF-8(コンマ区切り)を指定しておきます。
| No. | キーワード |
| 1 | ^hog |
| 2 | 3hoge |
| 3 | hoge |
csvファイルの読み込みはpandasモジュールがあると便利です。pip install pandasでインストールできます。
# csvファイル読み込み
import pandas as pd
df = pd.read_csv(r'C:\test\table.csv')
list(df["キーワード"])あとはエクセルから読み出した各キーワードを関数に入れ、ひたすら処理を繰り返し実行します。
# csvファイル読み込み
import pandas as pd
df = pd.read_csv(r'C:\test\table.csv')
grep_sakura(list(df["キーワード"])) {'^hog': 1, '3hoge': 1, 'hoge': 3}C:\test\result.logファイルは以下のようになります。
□検索条件 "^hog"
検索対象 *.txt
フォルダー C:\test
除外ファイル
除外フォルダー
(サブフォルダーも検索)
(英大文字小文字を区別しない)
(正規表現:bregonig.dll Ver.4.20 with Onigmo 6.2.0)
(文字コードセットの自動判別)
(一致した行を出力)
C:\test\test.txt(1,1) [UTF-16]: hoge
1 個が検索されました。
□検索条件 "3hoge"
検索対象 *.txt
フォルダー C:\test
除外ファイル
除外フォルダー
(サブフォルダーも検索)
(英大文字小文字を区別しない)
(正規表現:bregonig.dll Ver.4.20 with Onigmo 6.2.0)
(文字コードセットの自動判別)
(一致した行を出力)
C:\test\test.txt(2,3) [UTF-16]: 123hoge
1 個が検索されました。
□検索条件 "hoge"
検索対象 *.txt
フォルダー C:\test
除外ファイル
除外フォルダー
(サブフォルダーも検索)
(英大文字小文字を区別しない)
(正規表現:bregonig.dll Ver.4.20 with Onigmo 6.2.0)
(文字コードセットの自動判別)
(一致した行を出力)
C:\test\test.txt(1,1) [UTF-16]: hoge
C:\test\test.txt(2,4) [UTF-16]: 123hoge
C:\test\test.txt(3,4) [UTF-16]: foohoge
3 個が検索されました。これで検索キーワードが何百件あろうが、コマンドひとつでgrep検索を実行できるツールが完成しました!
このツールの機能を更に拡張・改良する場合、以下のようなアプローチが考えられます。
- キーワード検索のヒット数をエクセルファイルに追記する。
- オプションの指定方法をより使いやすい形にリファクタリングする(複数のファイル、ディレクトリを条件に指定するときにリスト型で個別に渡す。オプションも個別にフラグとして実装するなど)。
- デフォルトオプションをより使いやすいものに修正する。
まとめ
今回はPythonからサクラエディタを呼び出して検索処理の繰り返し作業を自動化しましたが、このプロセスはプログラミング言語、ツールを問わず使えます (プログラミング言語としてはPythonを使うと試行錯誤がしやすい、様々なモジュールがあり他のシステムと連携しやすいという点でおすすめです)。
自動化のアプローチ方法は基本的には以下のような流れで行っていくとよいと思います。
- 手作業が発生する作業で、単純処理、繰り返し処理があり、時間がかかっているものを探す。
- 入力、出力がプログラムで扱えるものにできるか検討 (テキストファイル、エクセルファイル、画像ファイルなど)。
- プログラムで処理できそうな範囲について、単一処理の動作確認用のプログラムを書いてみる。
- うまくいきそうなら関数化する、オプション機能を追加するなど作りこみ。
- ループ処理に組み込み、複数データを処理できるようにする。
- 全体の処理フローを整理、作りこみ。
みなさんも普段の作業で面倒だなと思っている作業があったら、本記事のやり方を参考に作業の自動化を試してみてください。
参考文献

