
#3【行列の探求】Python3データ分析試験に向けて(pandas/Matplotlib編)

こんにちは。グローバルウェイの内芝です。
「【行列の探求】Python3データ分析試験に向けて」と題し、シリーズで記事をお届けしています。前回は「NumPyの特徴・使い方」、「NumPyの基本的なメソッド」について解説しました。
ご覧になっていない方はそちらもぜひご覧ください。
第3回のテーマは以下となります。
今回のテーマ
・pandasの特徴・基本的な使い方
・pandasにおける要素へのアクセス、転置、定数倍
・Matplotlibの特徴・基本的な使い方
・Matplotlibにおける描画オブジェクト(figure)とサブプロット(axes)
ご興味を持たれた方はぜひ見ていってください!
目次
1|行列とは何かの復習
pandasやMatplotlibの理解において、行列の詳細な数学的知識は知らなくても大丈夫かと思います。(知っているに越したことはないですが)
どちらかというと、基本的な行列の概念への理解があればわかりやすいと感じます。
第1回で解説した「行列とは何か」という部分ですね。
※行列とは(おさらい)
行列とは「複数の数を縦横に並べてひとまとめにしたもの」であり、横に並んだ列を行列の行、縦に並んだ列を行列の列と呼び、〇 行 △ 列の行列と呼んで、その形を表します。
また行列内の各値を要素と呼び、i 行 j 列成分はをaijとして表します。
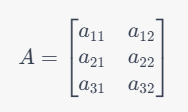
※たとえば
3行2列の行列Aは左のように示します。(3×2の行列という)
また、a11は第1行第1列の要素と言います。
2|pandas
2-1|pandasとは
pandasはデータの読み込み、加工、分析を行うための強力なライブラリです。
pandasには「Series(シリーズ)」と「DataFrame(データフレーム)」の2つのデータ構造があります。
pandasのデータ構造
Series:一次元データを格納する
DataFrame:行と列から構成されるExcelのような表形式の二次元データを格納する
DataFrameはSeriesを複数合わせたものとも捉えられますね。
試験ではほとんどDataFrameしか出てきません。
SeriesとDataFrameをそれぞれ実際に生成してみましょう。
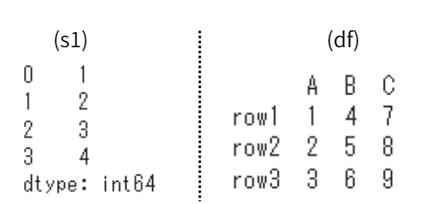
| pandasをpdとしてimportする import pandas as pd Seriesを作成 s1 = pd.Series([1,2,3,4]) dfのデータを作成する data = [ [1, 4, 7], [2, 5, 8], [3, 6, 9] ] column_names = ['A', 'B', 'C'] # 列名定義 index_names = ['row1', 'row2', 'row3'] #行名定義 DataFrameを作成 df = pd.DataFrame(data, index=index_names, columns=column_names) |
s1とdfをそれぞれprintすると、以下のようなSeriesとDataFrameが生成されます。
Seriesは一列のデータで数値なら数値のみ、同じデータ型のデータを扱います。
一方でDataFrameは複数の列を持つデータです。各列ごとにデータ型を変えることができます。
2-2|要素へのアクセス
特定の要素にアクセスするためには、行と列の「ラベル名」または「位置(index)」を指定します。
▶ .loc[] :「ラベル名(行名/列名)」に基づいて要素にアクセスする
▶ .iloc[] :「位置(行番号/列番号)」に基づいて要素にアクセスする
例)先ほど生成したDataFrameにおいて「B 列 row2 」の値「5」にアクセスしてみましょう。

▶ .loc[] を使用する場合 (’行名’、’列名’で指定)
| df.loc['row2', 'B'] |
▶ .iloc[] を使用する場合(’行番号’、’列番号’で指定)
| df.iloc[1, 1] |
ilocにおける「-1」の意味とは
ちなみにilocで行番号または列番号に「-1」を指定すると、それは「最後の要素」を意味します。
例として、行番号・列番号に両方「-1」を指定してみましょう。
| df.iloc[-1,- 1] |
この式では、最終行のrow3および最終列のC列「C列row3」の値「9」を返します。
スライスでの抽出も可能
また「:」を使って、列や行ごと抽出する「スライス」も利用可能です。
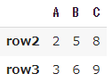
⓵locを利用して「row2からrow3」の行を抽出しましょう。(行範囲の指定 ['row2':'row3'])
| df.loc['row2':'row3'] |
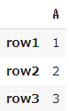
②ilocを使用して「A列」のみ抽出しましょう。(列範囲の指定 [0:1] )
行範囲には「:」を指定することで「全ての行を選択する」という意味になります。
| df.iloc[:,0:1] |
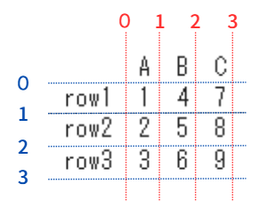
※ilocでスライスを利用する際のindexのイメージは、
以下のように要素の境界にあると考えると理解しやすいかと思います。
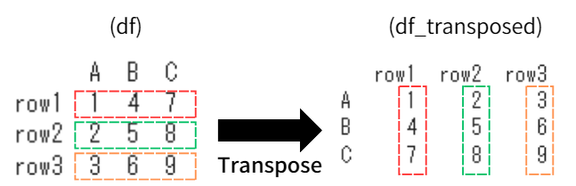
2-3|転置(Transpose)
.T 属性を使用することで、DataFrameの行と列を入れ替えることができます。
これは行列の転置の概念にとても近いですね。
| import pandas as pd data = [ [1, 4, 7], [2, 5, 8], [3, 6, 9] ] column_names = ['A', 'B', 'C'] # 列名定義 index_names = ['row1', 'row2', 'row3'] #行名定義 df = pd.DataFrame(data, index=index_names, columns=column_names) DataFrameの転置 df_transposed = df.T |
2-4|スカラー倍(定数倍)
基本的な行列演算の一つであるスカラー倍(行列の各要素に同じ数を掛けること)と同様の操作もpandasでは可能です。
スカラー倍を行列の数式で示すと以下のようになります。
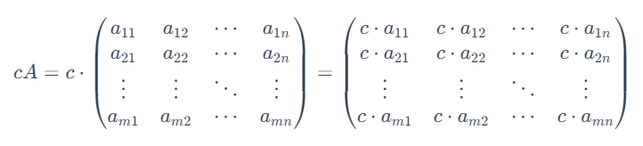
m×n の行列Aにスカラー(定数) c を掛けると、
結果は元の行列の各要素がc倍された行列となります。
pandasでも同じように、2-3で生成したdfに2を掛けると、各要素を2倍したdf_scaledを生成できます。
| # DataFrameのスカラー倍 df_scaled = df * 2 |
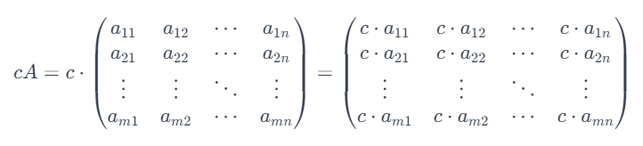
3|Matplotlib
3-1|Matplotlibとは
Matplotlibは「Pythonのグラフ描画用ライブラリ」で、様々なグラフを作成しデータを可視化することができるツールです。
とりあえずグラフを作成してみましょう。
例)y=sinx (0≦x≦2π) を描画してみる
| import matplotlib.pyplot as plt import numpy as np fig, ax = plt.subplots() x = np.linspace(0, 2*np.pi, 100) y = np.sin(x) ax.plot(x, y) plt.show() |
Numpyも一緒に利用して、これだけのコードで以下のようなグラフ作成ができてしまいます。
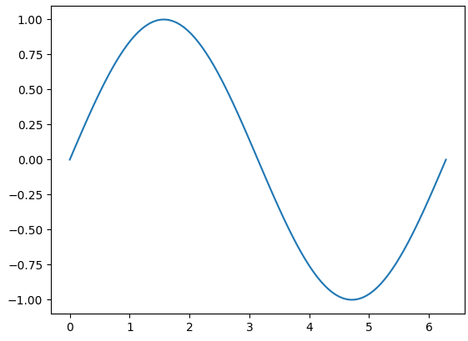
コードの流れを簡単に説明すると以下のようになります。
⓵Matplotlibのインポート
| import matplotlib.pyplot as plt |
基本的にpyplotモジュールを使用してグラフを描きます。(慣例として「plt」で略称)
②描画オブジェクトとサブプロットの生成(※オブジェクト指向インターフェース)
| fig, ax = plt.subplots() |
③ プロットするデータを準備
| x = np.linspace(0, 2*np.pi, 100) y = np.sin(x) |
④サブプロットに準備したxとyをプロットして、折れ線グラフ(曲線)を描画
| ax.plot(x, y) plt.show() |
3-2|Matplotlibのグラフの構成要素
Matplotlibの基本となるパーツは描画オブジェクト(figure)とサブプロット(axes)です。
3-1で出てきた以下のコードでは、引数を指定せずにsubplots関数を利用しているので
1つのfigureオブジェクトと、その中に1つのサブプロットを生成しています。
(それぞれ変数 fig,axに格納している)
| fig, ax = plt.subplots() |
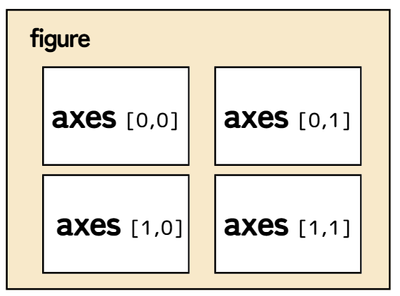
イメージはこんな感じです。

それぞれを詳しく説明すると、
描画オブジェクト(figure)
描画オブジェクトはグラフを描画する領域全体(キャンバス)です。
描画オブジェクトには、1つ以上のサブプロットが含まれます。
キャンバスのサイズや背景色、枠の色、タイトルを設定したり、
サブプロットの追加やレイアウト変更、作成したキャンバスの保存などを行えます。
サブプロット(axes)
サブプロットは描画オブジェクト内に存在し、グラフを描く個々の描画領域を表します。
棒グラフや散布図など、実際のグラフの描画を行うのはサブプロットです。
グラフの軸(X軸やY軸)、グラフタイトル、マーカー、ラベル、凡例などの要素を設定できます。
描画オブジェクトとサブプロットの関係性は例えると、「マンション」と「個々の部屋」みたいなもので、個別の部屋のレイアウトはサブプロットで行うイメージです。
またsubplots関数に引数を指定することで、
figureオブジェクトの中に複数のサブプロットを配置することもできます。
(nrows×ncols)個のサブプロットを生成する際は以下のように記述します。
| fig, axes = plt.subplots(nrows, ncols) |
例えば、2行2列の合計4個のサブプロットを全体の描画領域(figure)に生成してみましょう。
| fig, axes = plt.subplots(2,2) |
4つの各サブプロットに異なるグラフを描画できます。
各サブプロットは行列でいう「要素」として理解できますね。
行と列がインデックスで指定されており、各サブプロットは以下のように表せます。
左上:axes[0, 0]
右上:axes[0, 1]
左下:axes[1, 0]
右下:axes[1, 1]
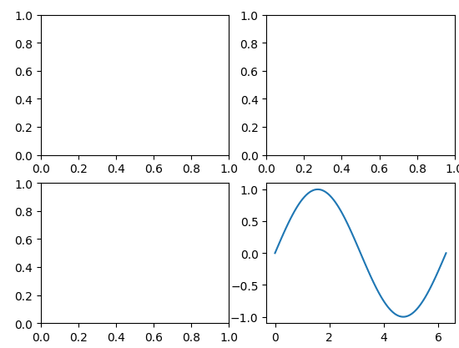
せっかくなので、右下のサブプロットaxes[1,1]に3-1で生成したy=sinxのグラフを描画してみましょう。
| import matplotlib.pyplot as plt import numpy as np fig, ax = plt.subplots(2,2) x = np.linspace(0, 2*np.pi, 100) y = np.sin(x) ax[1,1].plot(x, y) plt.show() |
描画オブジェクトに4つのサブプロットが現れ、2行2列目のサブプロット(axes[1,1])にsinカーブが描けました。
続いて、1行1列目のサブプロット(axes[0,0])に雪の結晶を描いてみましょう。
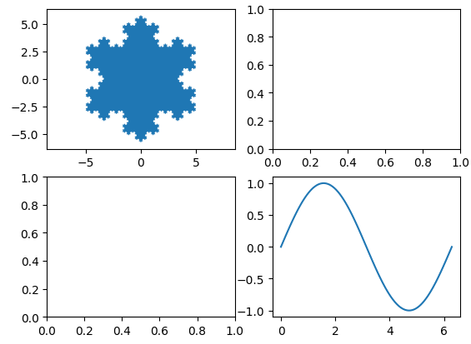
雪の結晶を描くコードは長くなるので書かないですが、Matplotlibの公式ドキュメントのExampleでご覧いただけます。
Filled polygon — Matplotlib 3.8.2 documentation
4|おわりに
本記事では、シリーズ第1回で学習した行列の基礎知識を元にしながら「pandasとMatplotlibの特徴と基本的な使い方」について解説しました。
NumPyと比較すると、pandasとMatplotlibを理解するうえで「行列」の高度な数学的知識はそれほど重要ではないと思います。特にデータ分析について学習し始めて間もなく、数学への苦手意識が強い方であれば「行列」の学習は必要になるまで後回しにするのも一つの手ではないかと感じます。
ただ、せっかくデータ分析試験では「行列」が関与する問題も少し出題されるので、基礎的な概念に慣れ親しむことで、今後の学習時の心理的なハードルを減らせるといいなと思い、解説いたしました。
シリーズ記事は今回で終了となります。
第1回、第2回をご覧になっていない方はそちらもぜひご覧ください。
Python3データ分析試験学習の一助になれば幸いです!

